Metaの「V-JEPA 2」とは──動画から“世界を理解する”AIの新たなアプローチ

画像出典:INTRODUCING V-JEPA 2 A self-supervised foundation world model
2025年6月、Meta(旧Facebook)は次世代の動画理解AIモデル「V-JEPA 2(Video Joint Embedding Predictive Architecture 2)」を発表しています。
同社はこのモデルを「AIが“行動する前に考える”ための世界モデル(World Model)」と位置づけ、人工知能の新たな発展段階を示しています。
本ブログでは、V-JEPA 2の概要、技術的特徴、活用可能性、そして現時点での課題を整理し、AI画像認識・ロボティクス分野の視点から読み解きます。
V-JEPA 2とは:動画から“世界モデル”を学ぶAI
V-JEPA 2は、動画データをもとに物理的な世界の変化を理解・予測・計画することを目的としたAIモデルです。
従来の画像認識AIが「静止画の分類」や「物体検出」を主なタスクとしてきたのに対し、V-JEPA 2は「時間的変化」や「因果関係」に焦点を当てています。
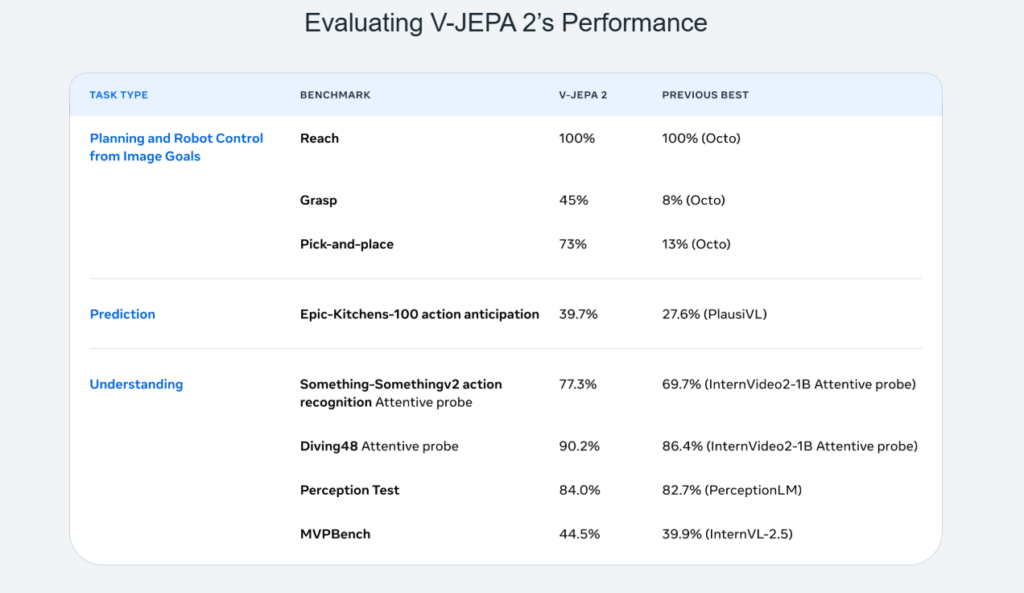
Metaによれば、このモデルは100万時間以上のインターネット動画を含む大規模な動画・画像データセットで事前学習を行いました。そして、動作理解タスクで優れた性能(Something-Something v2データセットでトップ1精度77.3%)を達成し、人間の行動予測タスク(Epic-Kitchens-100でリコール@5が39.7%)でも従来のタスク特化型モデルを上回る最先端の結果を示しました。
さらに、V-JEPA 2を大規模言語モデル(LLM)と統合した結果、8B(80億)パラメータ規模で複数の動画質問応答タスクにおいて最先端の性能を達成しました。具体的には、PerceptionTestで84.0%、TempCompassで76.9%というスコアを記録しています。
本モデルは、「現在の状況から次に何が起きるか」を推測し、将来的にはロボットや自律エージェントが現実世界で行動を計画するための基盤技術となることを目指しています。
同時にMetaは、V-JEPA 2の性能を評価するための3つの新しいベンチマークも公開し、動画AIの“物理理解力”を定量的に測定できるようにしています。これは、単なる精度競争から「理解力」評価への転換を意味します。
画像出典:INTRODUCING V-JEPA 2 A self-supervised foundation world model
技術的な特徴:ピクセルではなく“埋め込み空間”で予測する
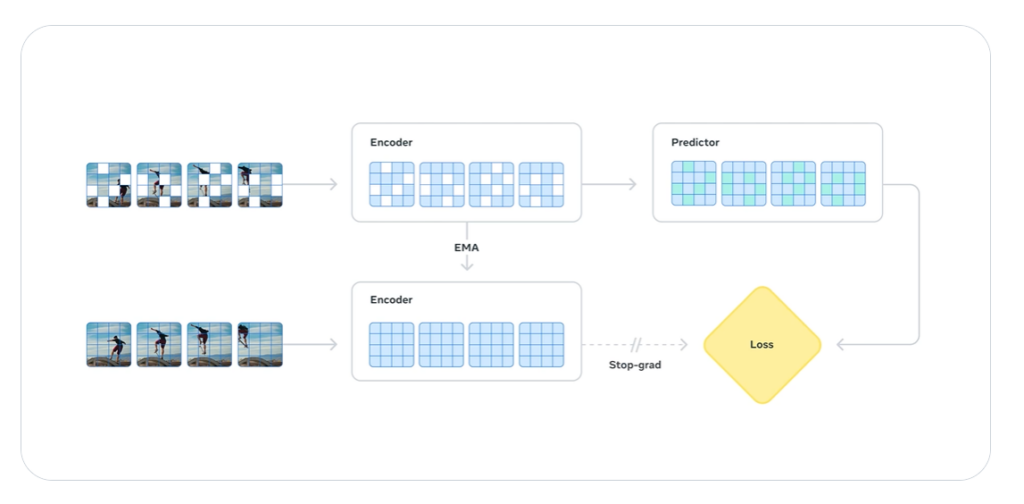
V-JEPA 2の最大の特徴は、「ピクセルを直接生成しない」という設計思想にあります。
多くの動画生成AIは、1フレームごとにピクセルを予測・生成しますが、これは膨大な計算リソースを必要とし、またノイズや不確実性が高くなります。
画像出典:INTRODUCING V-JEPA 2 A self-supervised foundation world model
V-JEPA 2は、映像をまず高次元のベクトル表現(埋め込み=embedding)に変換し、その変化を予測します。
つまり「意味的な空間(semantic space)」で“次に起こること”を推定するため、学習効率が高く、ノイズにも強いのが特徴です。
この仕組みにより、モデルは「ピクセルの変化」ではなく、「物体の動き」「関係性」「力学的影響」などの構造的情報を学ぶことができます。
Metaはこの方法を「AIが世界を“見て理解する”だけでなく、“考えて予測する”段階へ進む第一歩」と位置づけています。
画像出典:INTRODUCING V-JEPA 2 A self-supervised foundation world model
学習構造:アクションなし→アクション付きの2段階プロセス
V-JEPA 2の学習は、以下の2段階で構成されています。
- アクションなし自学習(大量の動画データ)
インターネット上の動画を用い、ラベルなしで状況の変化を学習。
たとえば、人が歩く・ボールが転がる・水が流れるといった日常的な動きのパターンを理解します。
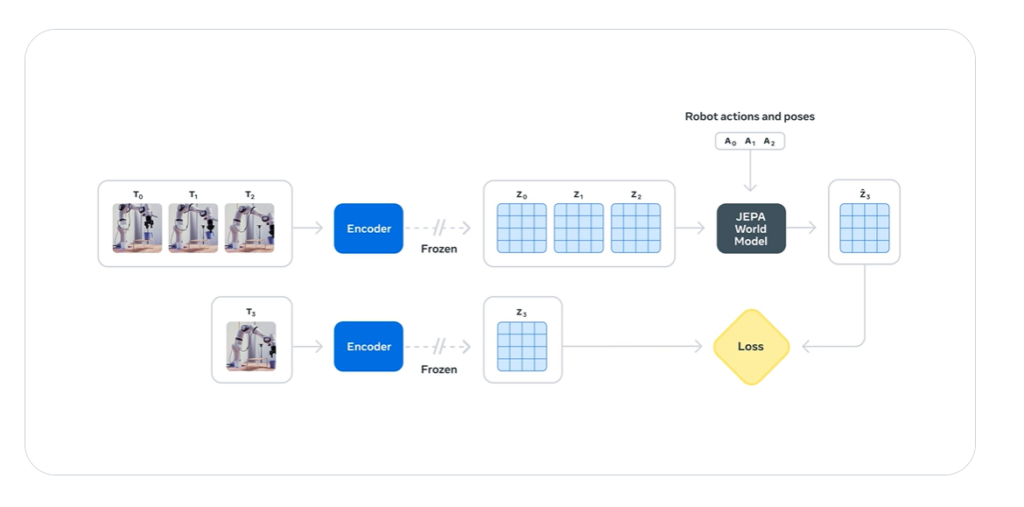
これは「世界の一般的なルール」を獲得する段階に相当します。 - アクション条件付き学習(ロボット操作データ)
次に、ロボットが実際に物体を掴む・動かすといった行動データを加え、「自分の行動が環境にどう影響するか」を学びます。
この段階では因果関係と計画性が求められます。
この二層構造により、V-JEPA 2は「見るAI」から「行動を理解するAI」へと進化しています。
V-JEPA 2のメリット:理解・予測・計画を統合
V-JEPA 2のアプローチには、次のような明確なメリットがあります。
- 動画理解の効率化
埋め込み空間での予測により、ピクセル生成型モデルより軽量・高速。
長時間動画の学習にも向いています。 - ゼロショットでの汎用性
特定の環境で学んだ行動モデルを、未知の環境にもある程度転用可能。
ロボットが新しい物体を扱うタスクでも一定の成果が報告されています。 - 世界モデルとしての拡張性
単なる分類や検出ではなく、物理的推論・行動予測まで一貫して扱える構造。
今後の「汎用人工知能(AGI)」への布石とされています。
このように、V-JEPA 2は “理解” “予測” “計画” という3段階の知能プロセスを統合的に扱う点で、従来のAIとは一線を画しています。
課題と今後の展望:万能ではない「世界モデル」
一方で、V-JEPA 2には現時点でいくつかの課題も存在します。
- 現実世界の複雑さへの対応
動画データは撮影条件や視点の多様性が大きく、埋め込み空間の設計次第では「物理的な一貫性」が崩れるリスクがあります。 - 学習データの品質依存
Web動画由来のノイズや偏りをそのまま学習すると、誤った因果関係を形成する可能性があります。 - 行動への還元問題
世界モデルで「予測」できても、実際の行動制御(ロボット操作)に接続するにはリアルタイム制御や安全性の課題が残ります。
Meta自身もV-JEPA 2を「最終形」ではなく、「AIが行動前に考えるようになるための中間段階」として位置づけています。
まとめ:画像認識から“世界理解”へ─AIの次の進化段階
V-JEPA 2の登場は、AI画像認識の進化方向を象徴する動きです。
これまでAIは「何が映っているか」を識別する存在でしたが、
今後は「それがどう動くか」「どうすれば目的を達成できるか」を理解・予測する存在へと変化していきます。
Metaが提唱する“世界モデル”は、単なるロボット制御の枠を超え、将来的には自動運転、AR/VR、デジタルツインなど、
現実世界を理解しながら判断するAIシステムの基盤技術として拡がる可能性があります。
まだ研究段階ではありますが、V-JEPA 2は「AIが世界をどう“見る”か」から「AIが世界をどう“理解して行動する”か」への転換点を示した意義ある発表といえるのではないでしょうか。
今後も最新技術ウォッチの一貫として、Metaの技術発表も注目していきたいと思います。
参考元
INTRODUCING V-JEPA 2 A self-supervised foundation world model
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Introducing the V-JEPA 2 world model and new benchmarks for physical reasoning
Meta発表の技術関連ブログ
DINOv3 Metaが開発・公開した新しいコンピュータビジョンモデル~その利用方法と可能性とは~
SAM2〜画像認識AIが進化中
マルチモーダル基盤モデル解説〜Metaの視覚言語統合AI
弊社では、常に最新技術の研究開発や検証、現場ナレッジの蓄積と最適な現実解を求め、貴社に寄り添った課題解決を提案していきます。
ぜひお気軽にお問い合わせください。
Contact us
お問い合わせ
画像認識をはじめとするAIのことなら是非OkojoAIに!ご相談ベースで構いませんので、遠慮せずお気軽にお問い合わせください。


