SAM・SAM2・SAM3・SAM3Dを比較解説
Segment Anythingの進化から見る最新画像認識AIの技術トレンド
Metaが公開してきた「Segment Anything」シリーズは、画像認識AIの基盤モデル化を象徴する研究として注目されています。
初代SAMから動画対応のSAM2、概念理解を強化したSAM3、さらに三次元理解へ拡張するSAM3Dまで、視覚AIの役割は段階的に進化しています。
本記事では、それぞれの技術的特徴、注目ポイント、そして現実的な活用例を比較しながら整理します。
Segment Anythingシリーズの位置づけ
従来の画像認識は、分類・検出・セグメンテーションといった個別タスクごとにモデルを構築するのが一般的でした。SAMシリーズはこれを「Foundation Vision Model」として統合し、汎用的な領域抽出を基盤に様々な応用へ拡張する思想を採用しています。
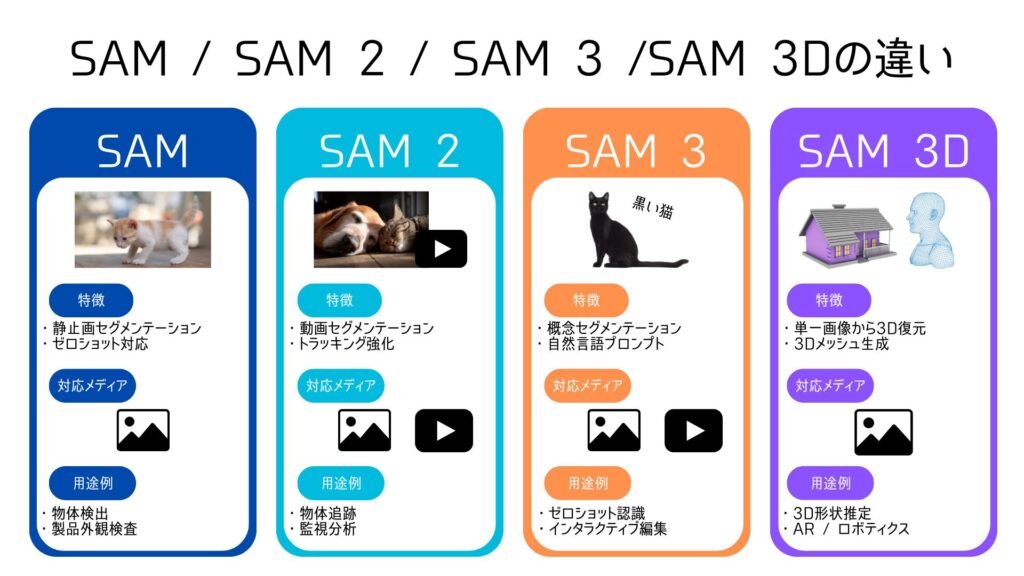
この進化の流れは大きく以下の4段階に整理できます。
- SAM:静止画向け汎用セグメンテーション
- SAM2:動画・トラッキング対応
- SAM3:概念理解・自然言語プロンプト対応
- SAM3D:3D形状理解への拡張
画像:各参考情報をもとに独自作成
SAM:画像セグメンテーション基盤の確立
初代SAMは、ゼロショットで様々な対象を分割できる汎用セグメンテーションモデルです。クリックやバウンディングボックスなど簡易な指示で対象を抽出でき、画像認識の前処理を大きく効率化しました。
技術的注目点
- Promptable Segmentationによる汎用ROI抽出
- 大規模データ学習によるゼロショット性能
- 下流タスクの共通前処理として利用可能
活用想定
- 製造業の外観検査ROI抽出
- アノテーション作業の自動化
- 画像編集・データ整備
SAM2:動画理解とトラッキングの強化
SAM2では静止画中心だった設計が拡張され、動画フレーム間の一貫性を考慮したセグメンテーションが可能になりました。対象物の追跡や動作解析など、動的シーンへの対応が特徴です。

画像出典:Introducing Meta Segment Anything Model 2 (SAM 2)
技術的注目点
- フレーム間情報を利用したトラッキング
- 動画セグメンテーションの統合処理
- 時系列データ対応の視覚表現
活用想定
- 監視映像の人物・物体追跡
- 作業工程の動作分析
- 異常行動検知の前処理
▼関連ブログ
SAM3:概念理解と自然言語プロンプト
SAM3では、単なる領域抽出を超え、「意味」や「概念」を理解するセグメンテーションへ進化しています。自然言語による指示が可能となり、動的なカテゴリ設定やオープンボキャブラリ認識が現実的になりました。
画像出典:Introducing Meta Segment Anything Model 3 (SAM 3)
技術的注目点
- 概念ベースのセグメンテーション
- 自然言語入力との統合
- 画像・動画の両方への対応
活用想定
- 大量映像のゼロショット検索
- インタラクティブ画像編集
- 非定義カテゴリの物体抽出
▼関連ブログ
MetaのSegment Anything Model 3のポテンシャルとは
SAM3D:画像認識から3D空間理解へ
SAM3Dは、セグメンテーション結果を基に対象物の三次元形状や姿勢を推定する研究的拡張です。従来の2D認識を空間理解へ拡張する点が特徴で、単一画像からの3D推定が試みられています。

技術的注目点
- 2Dマスクと3D形状推定の統合
- 単眼画像からの構造推論
- 人体・一般物体のモデル分離
活用想定
- ロボットの把持位置推定
- 作業姿勢の3D解析
- AR・デジタルツインの簡易生成
▼関連ブログ
技術進化から見る画像認識AIの方向性
SAMシリーズの進化を整理すると、視覚AIのトレンドが明確に見えてきます。
- 静止画 → 動画 → 概念理解 → 空間理解
- 個別モデル → 基盤モデル化
- ラベル依存 → ゼロショット化
特にSAM3以降は、視覚と言語の統合が進み、画像認識が単なる検出技術から「意味理解」へ移行していることがわかります。
導入検討時のポイント
実務導入では、目的に応じて段階的に選択するのが現実的です。
- 外観検査やアノテーション:SAM
- 動画解析や監視:SAM2
- 柔軟なカテゴリ認識:SAM3
- 空間理解やロボット用途:SAM3D(研究段階を考慮)
また、3D推定は不可視部分の推論限界があるため、精密計測の完全代替ではありません。
まとめ
Segment Anythingシリーズは、画像認識AIを基盤モデルとして統合し、動画理解、概念認識、三次元空間理解へと進化してきました。SAMはROI抽出の共通基盤を提供し、SAM2は動的シーン対応を強化、SAM3は意味理解を拡張し、SAM3Dは空間認識への可能性を示しています。
今後はFoundation VisionとマルチモーダルAIの統合により、現実世界をより深く理解する視覚AIへ発展していくことが期待されます。
弊社においても、引き続き最新技術情報の確認や検証を行い、異常検知や監視、予兆保全などお客様の課題解決のための一助となるよう努めてまいります。
お気軽にお問い合わせください。
▼参考元
Introducing Meta Segment Anything Model 2 (SAM 2)
Introducing Meta Segment Anything Model 3 (SAM 3)
▼関連ブログ
MetaのSegment Anything Model 3のポテンシャルとは
Metaの「V-JEPA 2」とは──動画から“世界を理解する”AIの新たなアプローチ
DINOv3 Metaが開発・公開した新しいコンピュータビジョンモデル~その利用方法と可能性とは~
まずはお気軽にご相談ください。
Contact us
お問い合わせ
画像認識をはじめとするAIのことなら是非OkojoAIに!ご相談ベースで構いませんので、遠慮せずお気軽にお問い合わせください。


