MetaのSegment Anything Model 3のポテンシャルとは
2025年11月19日、Meta が満を持してリリースしたSegment Anything Model 3(以下「SAM 3」)「は、「画像の中の特定のオブジェクトを自動で切り出す」「映像上で対象を追いかける」「言葉で “この要素だけ” を指定する」などのニーズに応える“汎用ビジョン基盤モデル”としての地殻変動を起こすポテンシャルを秘めています。
この記事では、SAM 3 の概要から技術的特徴、従来との違い、そして現実的な応用シーンまでを整理して紹介します。
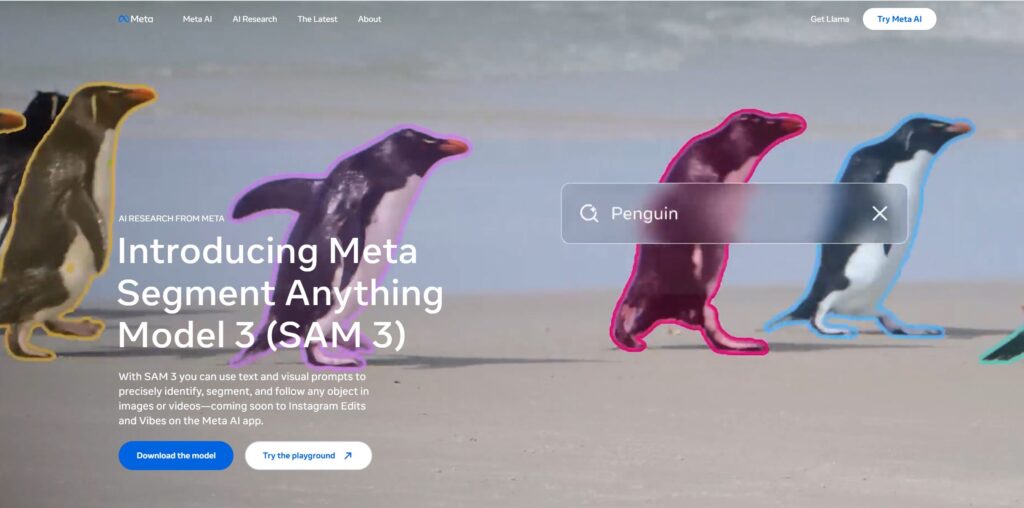
画像出典:Introducing Meta Segment Anything Model 3 (SAM 3)
SAM 3とは — 概要
SAM 3 は、画像および動画内のオブジェクトを、「検出 (detection)」「セグメンテーション (segmentation)」「トラッキング (tracking)」を統合的に行う Foundation Vision Model です。
特徴的なのは、ユーザーが “テキスト(例:「yellow school bus」「red apple」など短い名詞句)”、または “例として示す画像 (exemplar)” を使って「この概念に該当するすべてのオブジェクト」を指定できる点。さらに、従来のようなポイントクリック/バウンディングボックスの手動指定だけでなく、自然言語や画像例を使った “オープンボキャブラリ (open-vocabulary)” な分割が可能になりました。

画像出典:Introducing Meta Segment Anything Model 3 (SAM 3)
また、静止画だけでなく動画にも対応 — 各フレームでの物体検出・分割に加えて、追跡 (tracking) によるインスタンスの一貫性維持も可能です。
Meta は、モデルのチェックポイント (weights)、推論およびファインチューニング用コード、そして新しいベンチマーク “SA‑Co Dataset” を公開し、研究者/開発者がすぐに利用できるようにしています。
技術的な仕組みと注目ポイント
SAM 3 のアーキテクチャは、以下のような要素から構成されています。
●共通ビジョン backbone
画像や映像を特徴量としてエンコードする基盤となるエンコーダーを共有。これにより、静止画・動画、プロンプト種別 (テキスト/画像例/視覚的入力) をまたいだ柔軟な処理が可能。
●DETR 風の Promptable Detector
従来の “1対象ずつ/1プロンプトずつ” のセグメンテーションではなく、テキストや画像例に応じて、概念 (コンセプト) に属するすべての対象インスタンスを一括で検出・切り出す設計。
●メモリベースの Video Tracker + Presence Head
検出されたオブジェクトを動画の各フレームで追跡するモジュールに加え、「その概念を持つオブジェクトが本フレームに存在するかどうか」を判定する “presence head” を導入。これにより、オブジェクトの重複や誤検出を抑えつつ安定したトラッキングが実現されています。
さらに、Meta は新たに SA-Co データエンジン を構築。約 4 百万以上のユニーク概念 (visual concept) を自動アノテーションし、その中から約 27 万の“評価済みユニーク概念 (unique concepts)” をもつベンチマークを整備。これは、従来のオープンボキャブラリ・セグメンテーションで扱っていた概念数の 50倍以上 に相当します。
結果として、SAM 3 は従前のオープンボキャブラリ分割モデルを大きく上回る精度と安定性を獲得。Meta の報告によれば、SA-Co ベンチマークにおいて人間の cgF1 性能のおよそ 75〜80% を達成。
さらに、SAM 3 は映像処理用の「画像 → 動画 → 追跡」のワークフローの統一を可能にし、これまで分断されていた “静止画セグメンテーション/動画オブジェクト追跡” をひとまとめにした点でも画期的です。
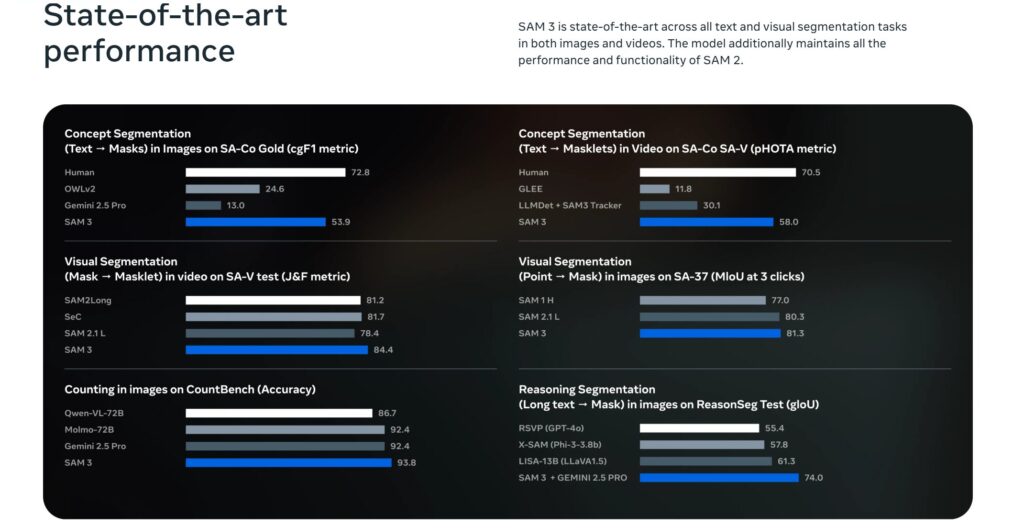
画像出典:Introducing Meta Segment Anything Model 3 (SAM 3)
従来からの進化 — なぜ “SAM 3” は特別か
これまでの世代である Segment Anything Model(SAM, 初版) や Segment Anything Model 2(SAM 2)は、非常に強力な “ポイントやボックスによるインタラクティブなセグメンテーション” を実現してきました。特に SAM (SA-1B データセット) によるゼロショット分割は、従来のラベル付きセグメンテーションを大きく凌ぐ柔軟性をもたらし、 “どんな形式の画像にも対応できるラベル不要モデル” というビジョンを示しました。
しかし、それでも「人がクリックや枠指定で対象を教える必要がある」「複数同タイプのオブジェクトを一度に分割するには手間がかかる」「動画には弱い」といった制限が残っていました。
SAM 3 は、まさにその “実用上の限界” を超えるためのアップデートです。
- 自然言語や画像例で指定可能なオープンボキャブラリ分割 → 手動指示不要でスケール化が容易
- 一度にすべてのインスタンスを検出・分割 → 大量画像/動画のバッチ処理や自動化が可能
- 画像と動画の統一ワークフロー → コンテンツ制作/編集、映像解析、リアルタイム処理など幅広い用途に対応
これにより、SAM 系が理論実験や研究用途に留まらず、実務・プロダクトへの適用がぐっと現実味を帯びたのです。

画像出典:Introducing Meta Segment Anything Model 3 (SAM 3)
応用想定ユースケース
SAM 3 の汎用性と柔軟性を活かすと、さまざまなビジネス領域で “セグメンテーション+トラッキング” をキーに新たな価値を生み出せると考えます。
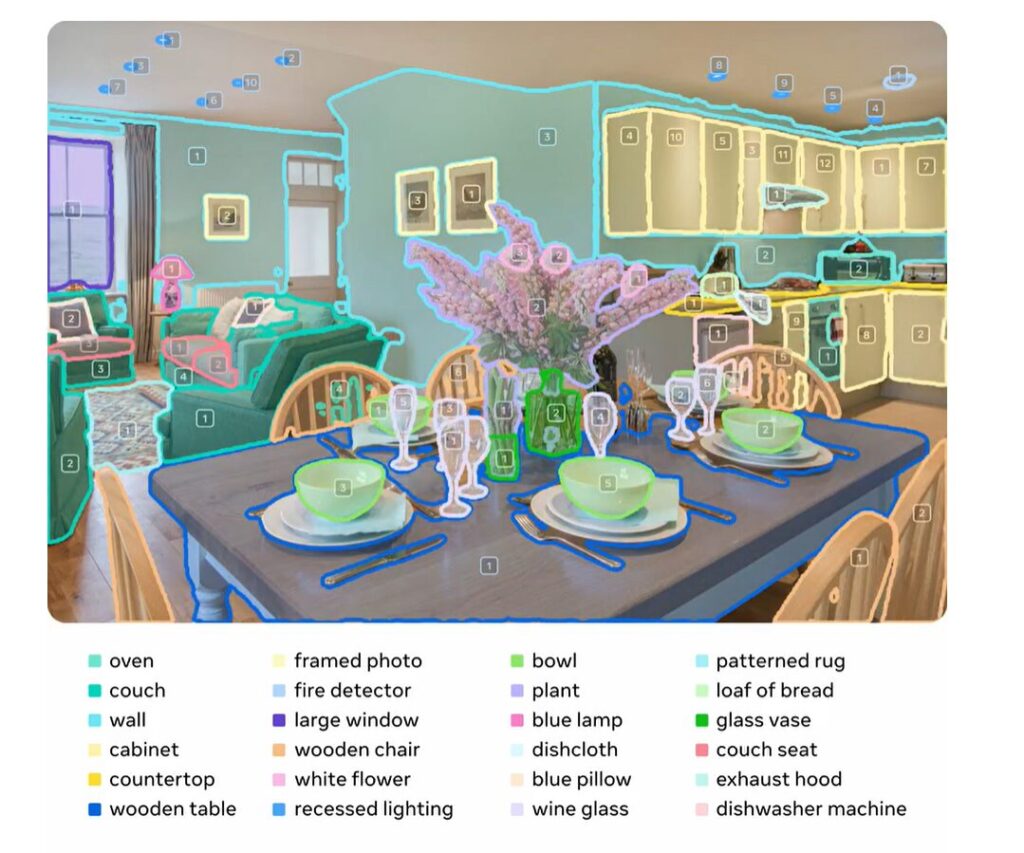
画像出典:Introducing Meta Segment Anything Model 3 and Segment Anything Playground
●Eコマース / プロダクト写真
商品写真で背景を自動除去 → 白背景への切り出し、複数の画像から商品の一貫したマスク取得 → 360°表示、バリエーション画像生成、背景差し替えなど
●広告・マーケティング / クリエイティブ制作
「赤い服の人々」「スマホを持つ手」「空」「特定の風景」など、任意のコンセプトをテキストで指定 → マスク取得 → 背景差し替え、エフェクト追加、静止画/動画広告の自動生成
●動画編集 / VFX / 映像ポストプロダクション
映像内の特定オブジェクト (車、人、動物など) を自動で追跡/マスク → トラッキング → 被写体の除去、差し替え、モーショングラフィックス挿入
●データセット構築 / アノテーション代替
画像・動画データのラベル付けコストを大幅に削減 ―― ゼロショットまたは少量の例 (exemplar) で一括マスク生成。特に大量の映像データや、頻繁に変わる商品ラインナップを持つ企業には大きなコスト削減効果
●AR / VR / インタラクティブコンテンツ
“言葉で指示 → オブジェクト抽出” というワークフローは、ARアプリやインタラクティブUIでの自然な操作設計に強み。例えば “テーブルの上のコップだけ選んで拡大表示”、 “部屋の物体を認識して配置切り替え” など
●マルチモーダルAIとの統合
映像/画像データとテキスト (自然言語)、あるいは生成AI (画像生成、合成) を組み合わせるワークフローで、SAM 3 を “視覚理解エンジン” として使うことで、より高度なマルチモーダルアプリケーションを構築可能
●映像解析 / 監視 / IoT / 自動運転関連
動画内で人、車、物体などを検出・追跡 → ロギング、行動解析、異常検出、リアルタイム通知など。産業用途や安全管理用途でも応用に耐える
まとめ
SAM 3 は、単なる “新しいセグメンテーションモデル” ではなく、画像・動画処理のワークフローにおける “プラットフォーム的転換点” と位置づけられるモデルです。とくに以下のポイントを考慮すると、今後の活用が大変興味深いです。
- テキストや画像例によるオープンボキャブラリ分割 + 動画追跡の統一 — 従来分断されていたタスクを一本化
- 大規模データ (SA-Co) による学習とベンチマークにより、実用レベルの精度と汎用性を実現
- モデルチェックポイント、コード、ベンチマークの公開 ― “すぐ使える” オープンソースとして提供
つまり、SAM 3 は画像・動画を利用しAI技術をサービス化するための良い基盤となりうると考えられます。
ただし、利用にあたっては課題もいくつか考えられます。
例えば、モデルはかなり大きく(848M パラメータ)、高性能 GPU がないとリアルタイム性能を出すのは難しいことや、ロショットで多くの概念に対応可能だが、医療画像・顕微鏡画像・特殊環境下の画像といった「ドメイン固有・細かい構造」が求められる場面では、ファインチューニングやアダプターの併用が必要になる可能性があることなどです。
また、「オープンボキャブラリー」であるがゆえに、あいまいな表現や誤った概念を入力すると、誤ったマスクが返る — という入力品質の問題も否定できません。
今後の検証、利用等にあたっては、課題にも留意しながら、ケースごとに試していくことが必要です。
弊社では、引き続き最新技術、注目論文などを確認・検証しながら、よりお客様の課題解決に迅速に的確にお役に立てるようナレッジを蓄積していきます。
画像解析AI関連での課題やお悩みは、お気軽にご相談ください。
まずはPoCからご相談いただけます。お気軽にお問い合わせください。
Contact us
お問い合わせ
画像認識をはじめとするAIのことなら是非OkojoAIに!ご相談ベースで構いませんので、遠慮せずお気軽にお問い合わせください。