2026-02-23 / 最終更新日時 : 2026-02-15 bloguser 画像認識AISAM 3Dとは?画像認識AIを3D空間理解へ拡張する次世代セグメンテーション技術 近年、Metaが推進する画像認識AIの研究は、「Foundation Vision Model」という方向性へ進んでいます。その中でも注目されているのが、Segment Anythingの流れを三次元理解へ拡張した研究ア […]
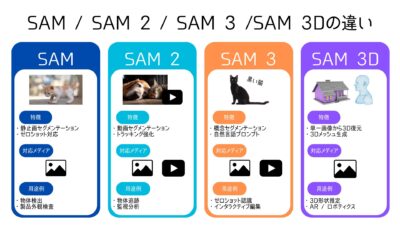
2026-02-16 / 最終更新日時 : 2026-02-15 bloguser 画像認識AISAM・SAM2・SAM3・SAM3Dを比較解説 Segment Anythingの進化から見る最新画像認識AIの技術トレンド Metaが公開してきた「Segment Anything」シリーズは、画像認識AIの基盤モデル化を象徴する研究として注目されています。初代SA […]
2025-12-12 / 最終更新日時 : 2025-12-05 bloguser 最新情報MetaのSegment Anything Model 3のポテンシャルとは 2025年11月19日、Meta が満を持してリリースしたSegment Anything Model 3(以下「SAM 3」)「は、「画像の中の特定のオブジェクトを自動で切り出す」「映像上で対象を追いかける」「言葉で […]
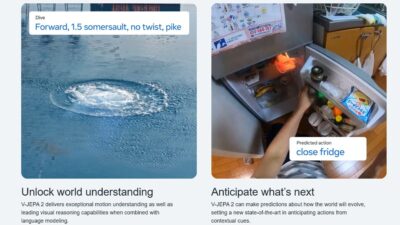
2025-11-28 / 最終更新日時 : 2025-11-25 bloguser 最新情報Metaの「V-JEPA 2」とは──動画から“世界を理解する”AIの新たなアプローチ 画像出典:INTRODUCING V-JEPA 2 A self-supervised foundation world model 2025年6月、Meta(旧Facebook)は次世代の動画理解AIモデル「V-JEP […]
2025-09-05 / 最終更新日時 : 2025-09-30 bloguser 画像認識AIDINOv3 Metaが開発・公開した新しいコンピュータビジョンモデル~その利用方法と可能性とは~ 2025年8月、Meta AI(旧Facebook AI Research)は、自己教師あり学習(Self-Supervised Learning, SSL)に基づく最新の視覚モデル「DINOv3」を発表しました。DIN […]