DINOv3 Metaが開発・公開した新しいコンピュータビジョンモデル~その利用方法と可能性とは~
2025年8月、Meta AI(旧Facebook AI Research)は、自己教師あり学習(Self-Supervised Learning, SSL)に基づく最新の視覚モデル「DINOv3」を発表しました。
DINO(Distillation with No Labels)シリーズの第3世代となる本モデルは、従来の教師あり学習のように「ラベル付きデータ」を必要とせず、大規模な未ラベル画像から汎用的な視覚特徴を学習します。
このアプローチは、AIの開発において大きなボトルネックだった「アノテーションコスト」を解消し、あらゆる分野で応用可能な基盤モデル(Foundation Model) として注目されています。MetaはDINOv3をオープンソース化し、研究者や企業が自由に利用できる環境を整備しています。

画像の出典:Meta DINOv3
DINOv3の性能とは
DINOv3の技術的な強みは、その「スケール」と「特徴表現力」にあります。
DINOv3の特徴
超大規模学習
17億枚以上の未ラベル画像を用いて、ViT-7B(Vision Transformer、約70億パラメータ) を自己教師あり学習で訓練。これにより、微細な特徴を捉える密な表現を獲得しました。
Gram Anchoringによる安定化
長時間学習で起こる「特徴表現の劣化」を防ぐため、過去のモデルチェックポイントと現在の特徴マップの類似性を保つ Gram Anchoring 技術を導入。これにより学習が安定し、精度が大幅に向上しました。
高解像度対応
512px〜4Kといった高解像度画像に最適化されたトレーニングフェーズを追加し、医療画像や衛星写真など精細な分析が必要な領域でも利用可能になっています。
蒸留による軽量化
巨大モデルで得た知識を、小型のViT-S(21Mパラメータ)、ViT-B(86M)、ViT-L(300M)、ViT-H+(800M)へ蒸留。これにより、エッジデバイスやリアルタイム処理環境でも利用できる柔軟性を確保しました。
DINOv3の性能
実際、DINOv3は画像分類・物体検出・セグメンテーション・異常検知など幅広いベンチマークでSOTA(State-of-the-Art)を達成しています。
DINOv3 performance benchmarks
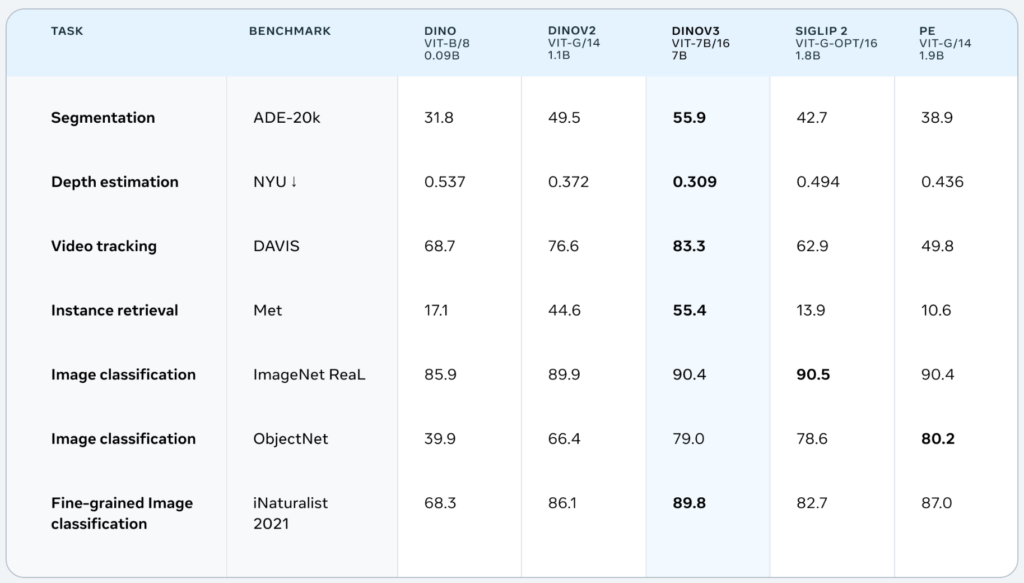
画像の出典:Meta DINOv3
DINOv3のメリット
DINOv3のメリットは、単なる大規模、高性能にとどまりません。
ラベル不要
自己教師あり学習のため、大量の未ラベルデータを直接利用可能。特に医療や製造業の異常検知など、ラベル付けが困難な領域で強みを発揮します。
汎用性の高さ
画像分類からセマンティックセグメンテーション、深度推定、トラッキングまで幅広く対応。「1つのモデルで複数タスク」をこなす汎用性は、従来の専門モデルを超える強みです。
即時利用可能なエコシステム
Metaは、モデル本体・学習コード・評価用ノートブックをオープンソースで公開。研究だけでなく、商用利用にもすぐに活用可能です。
ドメイン適応の容易さ
学習済みモデルをそのまま使う「凍結エンコーダー」としても優秀で、追加の学習を最小限に抑えて新しい領域に転用可能。小規模データでも高性能を発揮します。
DINOv3の利用例
DINOv3は様々な分野での活用が期待されています。
製造業における異常検知
工場ラインの画像やセンサーデータから、不良品や設備異常のパターンを自動検出。微細な傷や摩耗の兆候を早期に見つけることで、ダウンタイム削減に寄与します。
森林モニタリング(World Resources Institute)
ケニアの森林被覆高さを推定するプロジェクトでは、従来4.1mの誤差があった予測を、DINOv3導入後は1.2mまで改善。環境モニタリングにおける新しい基盤技術となっています。
宇宙探査(NASA JPL)
計算資源の制約が大きい火星探査ロボットでの視覚認識に利用され、軽量ながら高精度な処理を実現。未知の環境での探索を支える技術として注目されています。
医療画像解析
MRIとCT画像の位置合わせ(レジストレーション)にDINOv3を活用した研究では、Diceスコア0.79という高精度を達成。病変検出や治療計画支援への応用が期待されます。
DINOv3のまとめ
Metaが公開した「DINOv3」は、自己教師あり学習の可能性を大きく押し広げた画期的なモデルです。
- ラベル不要で高精度な画像認識AI
- Gram Anchoringや高解像度対応による安定性と柔軟性
- 巨大モデルから軽量モデルまで幅広いラインナップ
- 製造業・医療・環境・宇宙探査など幅広い産業応用
特に「製造業の異常検知」や「医療診断支援」といった分野では、従来のAI導入ハードルを一気に下げる存在となる可能性があります。
今後、DINOv3は「画像認識の万能バックボーン」として、生成AIやマルチモーダルAIとの連携も進み、ビジネスと社会の両面で革新をもたらすでしょう。
弊社においても、DINOv3の性能検証や利用ケースにおけるテストなどを継続し、異常検知や監視、予兆保全などお客様の課題解決のための一助となることを努めてまいります。
お気軽にお問い合わせください。
参考元
INTRODUCING DINOV3
RESEARCH DINOv3
DINOv3: Self-supervised learning for vision at unprecedented scale
お気軽にお問い合わせください。
Contact us
お問い合わせ
画像認識をはじめとするAIのことなら是非OkojoAIに!ご相談ベースで構いませんので、遠慮せずお気軽にお問い合わせください。


