SAM2〜画像認識AIが進化中
ここ3ヵ月(2025年7月~9月)に発表された、画像認識AI分野の注目論文や新技術の動向をご紹介の一貫として、SAM2をご紹介します。
生成AIばかりが話題になりがちな中、実は画像認識AIの進化も加速しています。最新の研究や手法を把握することで、これまで困難とされてきた課題の突破口が見え、品質検査や不良品検知、異物混入検査など現場での精度向上にも直結する可能性があります。
AIをこれから導入したい企業はもちろん、過去にAI導入で成果が出なかった経験をお持ちの方にとっても、再挑戦のチャンスが広がっています。
もしAIによる画像認識を活用した課題解決(例:原材料受入時の異常検知、品質管理、製造ラインでの品質検査など)をご検討中であれば、ぜひ最新技術の情報収集とともに、弊社までお気軽にご相談ください。
Segment Anything Model 2(SAM2)とは

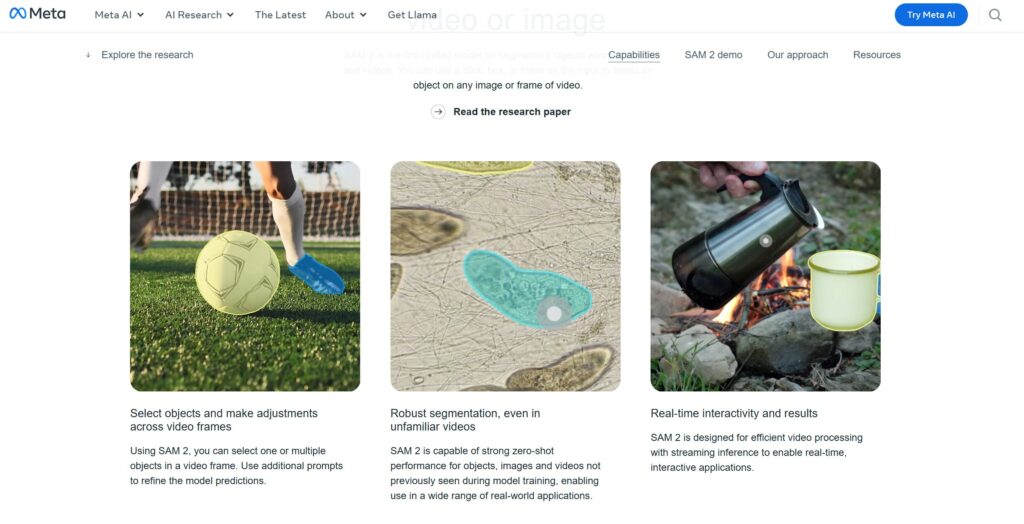
画像出典:Introducing Meta Segment Anything Model 2 (SAM2)
◆技術的要素
Meta AI Researchが開発した「SAM2」は、あらゆるビデオや画像内のあらゆるオブジェクトを高速かつ正確に選択できるセグメンテーション モデルです。
トランスフォーマーベースのアーキテクチャに時系列処理機能を統合し、静止画像から動画への拡張を実現しました。
プロンプト可能なセグメンテーション機能により、ポイント、ボックス、マスクなど様々な入力形式に対応し、ゼロショット転移学習により未知のオブジェクトカテゴリーも高精度で認識・追跡できます。メモリバンクメカニズムにより、長時間の動画でも一貫したオブジェクト追跡を維持します。
これまで、静止画像向けセグメンテーションモデルは多く存在しましたが、動画領域(時間軸をまたぐ対象追跡や再出現・遮蔽等を扱う)において、「プロンプト可能」「対話的」「高速処理可能」といった機能を兼ね備えたモデルは不足していました。SAM2はこのギャップを埋めることを目指して設計されています。
論文では、「ユーザーとのインタラクション(プロンプト)を通じてモデルとデータを改善するデータエンジン構成」「ストリーミングメモリ構造を備えた Transformerベースの設計」「速度と精度の両立」などを主軸として設計がなされています。
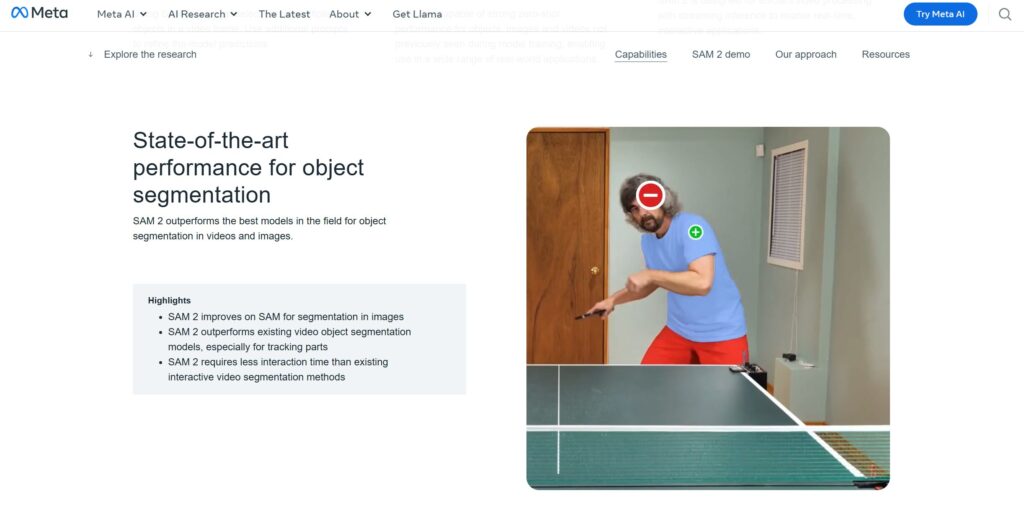
実験では、動画セグメンテーションにおいて従来モデルより少ないユーザー操作(インタラクション)で高精度を達成、また静止画セグメンテーションでは従来のSAMより精度と速度の双方で向上を示しています。
◆内部構造と主要技術要素
SAM2 の技術設計は、主に以下の構成要素と工夫から成り立っています:
- プロンプト可能なアーキテクチャ(Promptable Visual Segmentation)
- ストリーミングメモリ構造(Streaming Memory)
- エンコーダ・デコーダ構成と注意機構
- 学習データ構成と訓練手法(データエンジン、SA-V データセット等)
- 速度・効率化の工夫と最適化
画像出典:Introducing Meta Segment Anything Model 2 (SAM2)
◆プロンプト可能なアーキテクチャ
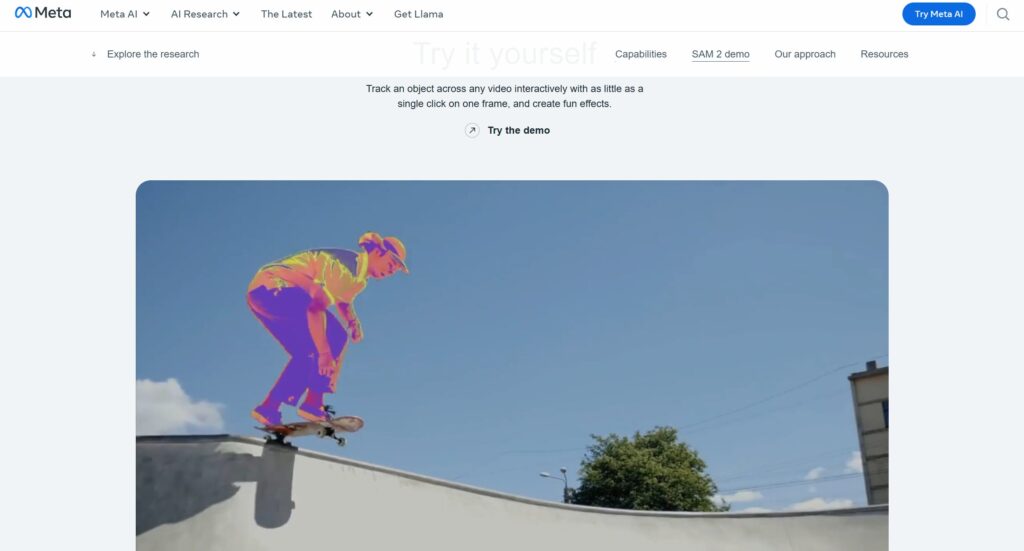
SAM2 は「プロンプト可能性(promptability)」を重要な特徴とし、ユーザー入力(プロンプト)をもとに対象を指定・修正できるよう設計されています。プロンプトの形式としては、点(ポイント click)、バウンディングボックス(矩形)、マスクなどが用いられます。
この設計により、ユーザーは対象物の大まかなエリア指定(ボックス)や細部の修正(点クリック)などを通じて、セグメンテーション結果を対話的に制御できます。静止画の場合はこれがそのまま機能し、動画の場合はこのプロンプトを起点として時間軸方向にマスクを伝播・補正するように設計されています。
プロンプトを受け取るための Prompt Encoder モジュールも設計されており、ユーザー入力を内部表現に変換し、マスク生成を導く制御信号として機能します。
◆ストリーミングメモリ構造
動画セグメンテーションを効率的に処理するため、SAM2はストリーミングメモリ(Streaming Memory)構造を備えています。
これは、過去フレームの情報(特徴表現やマスク予測等)を記憶して現在のフレーム処理に活用する仕組みです。
具体的には、モデルは動画をフレーム単位で逐次処理し、その都度、過去のフレーム情報(メモリバンク)を参照しながら注意機構で特徴を条件付けます。このメモリ構造により、遮蔽(オクルージョン)や対象の一時的な消失、再出現といった現象にも対応しやすくなります。
また、プロンプトを与えられた時点のフレーム情報だけでなく、「未来のフレーム(後の時刻のプロンプト)」を参照するような設計も可能とされており、時間的コンテキストを柔軟に活用する構造が取り入れられています。
画像出典:Introducing Meta Segment Anything Model 2 (SAM2)
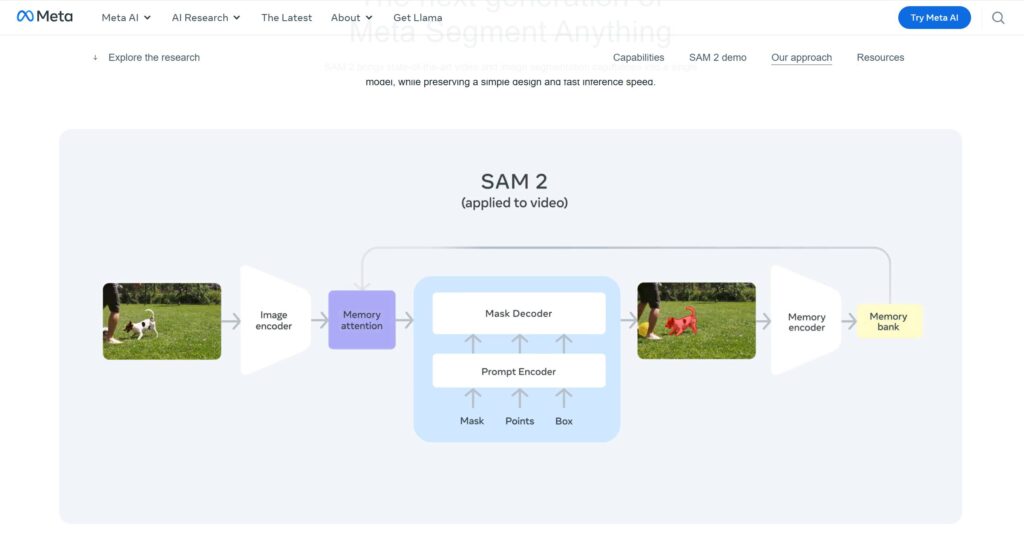
◆エンコーダ・デコーダ構成と注意機構
SAM2 の中心的なネットワーク構成は、画像(または動画フレーム)エンコーダ→メモリ条件付けモジュール→マスクデコーダという流れです。
画像/動画フレームエンコーダ
Hieraという構成を採用しており、マルチスケール特徴を捉えるような層構造がなされています。Hieraエンコーダはウィンドウベースの絶対位置
埋め込み(windowed absolute positional embeddings)を使用し、階層的な処理を可能にします。
メモリ条件付け(Memory Attention / Cross-Attention)
現在のフレーム特徴を、メモリバンク(過去フレームまたはプロンプトフレームの情報)と結合するために注意モジュールが用いられています。
具体的には、自己注意(Self-Attention)とクロス注意(Cross-Attention)を組み合わせる形で、フレーム間の特徴伝搬や時間的条件付けを行います。
マスクデコーダ
Prompt Encoderからの情報と、メモリ条件付け後のフレーム表現を入力として、最終的にセグメンテーションマスクを生成する部位です。
SAMのデコーダ構造を受け継ぎつつも、高解像度特徴を取り入れる設計などの改良が入っています。
画像出典:Introducing Meta Segment Anything Model 2 (SAM2)
◆学習データ構成と訓練手法
SAM2の優れた性能を支えているのが、大規模な動画セグメンテーションデータセットSA-V(Segment Anything–Video)と、モデル・データ共同改善型データエンジンの構造です。
SA-Vデータセット
- SA-V は、約51,000本の動画と600,000を超える“masklets”注釈を含む大規模動画セグメンテーションデータセットです。
- 視覚ドメイン・シーン種類を広くカバーし、屋内・屋外、照明条件・被写体バリエーションなど多様な映像を含んでいます。
- maskletsとは、各オブジェクトに対して時間軸を跨る連続的なマスクをまとめた単位で、プロンプト起点から時間的拡張がなされたマスク情報です。
- SA-Vは、従来公開されていたどの動画セグメンテーションデータよりも規模で圧倒的であり、モデルの汎化性向上を支える基盤になっています。
モデル・データ共同改善(Model-in-the-loop Data Engine)
論文では、単にデータを集めてモデルを学習するのではなく、「ユーザーインタラクション→データ補正/追加→モデル更新」というループ構造を導入しています。これを“data engine”と呼び、モデルとデータを相互に改善していく設計が採られています。
この手法により、モデルが“苦手な対象”を識別しながら、その対象に対する注釈データを強化して補正し、モデル性能を反復的に改善することが可能になります。ユーザー入力(プロンプト)からの補正がこのループに組み込まれています。
訓練手法と損失関数
- モデルは静止画像データ(SAMの既存データ)とSA-Vの動画データを交互に訓練対象に含めながら最適化されます。これにより、静止画セグメンテーション能力と動画追跡能力を両立させます。
- 損失関数には、マスク予測の損失(例:Focal Loss, Dice Loss)、IoU(Intersection over Union)レベルの誤差抑制損失、マスク適用可否(オブジェクト存在判定)損失などが組み合わせられています。
- 遮蔽(occlusion)したフレームではマスクが存在しないことを予測するヘッドも導入されており、無対象フレームを適切に扱う設計があります。
これらにより、モデルは強いゼロショット一般化能力、動画中の物体追跡能力、ユーザー最小操作性を兼ね備えるよう設計されています。
画像出典:Introducing Meta Segment Anything Model 2 (SAM2)
SAM2の強み・性能と制約・課題
SAM2の特徴的な強みとともに、既存論文や評価から見える制約・課題を整理します。
強み・性能面
- 高精度かつ高速なセグメンテーション
静止画セグメンテーションにおいて、元のSAMより精度が向上しつつ推論速度が約6倍速い
動画セグメンテーションでも、従来モデルより少ないユーザインタラクションで高精度結果を得られる - インタラクティブ性と少ないプロンプト負荷
ユーザーによるマスク修正やプロンプト入力を最小化しつつ、高精度マスクを出せるよう設計されており、対話的な用途で使いやすい - 動画追跡と遮蔽対応
ストリーミングメモリ構造により、遮蔽・消失・再出現といった現象に対応可能。 - ゼロショット一般化
事前学習したドメイン外対象にも対応できる能力があり、新たな対象物を訓練なしでセグメンテーション可能 - 大規模データ基盤
SA-V をはじめとした大規模注釈データとモデル・データループ構成により、汎化性および性能改善余地を確保
制約・課題・注意点
・長時間遮蔽や大規模カメラ変化
対象が長時間見えなくなる、カメラ視点変化が大きい場合などでは追跡性能が劣化する可能性があります。
これらは動画セグメンテーション一般の難所でもあります。
・微細構造・細い物体の分割精度
非常に細い対象、複雑な輪郭、重なりが激しい場面ではマスク境界の精度が落ちる可能性があります。
これを補うための追加プロンプトや後処理が必要になる場合があります。
・重み計算負荷・メモリ消費
メモリ付き注意処理、複数フレーム参照、メモリバンク管理などを伴うため、計算コスト・メモリ消費は大きくなり得ます。
リアルタイム動作が必須の場面では最適化が不可欠です。
もともと速度を重視する設計がなされているとはいえ、高解像度・多数オブジェクト処理ではボトルネックになる可能性があります。
SAM2の応用シーン例
SAM2の技術は、特に以下のようなシーンでの応用が期待できます。
- 製造業/品質検査用途:静止画・動画両方の対象を扱える点を活かし、不良品検知や異物混入検査、原材料・製品異常検知といった現場での画像認識タスクに応用可能性があります。特に、製品動作中や流動工程中の動画観察が可能なラインには適しています。
- 設備・インフラ点検:たとえば、受水槽点検、配管・タンク・建築構造物の劣化/亀裂/堆積物検知用途に、動画ストリームを使って異常個所をセグメントする用途として応用できる可能性があります。
- 対話型補正・インタラクティブ検査:現場オペレータが画面上でプロンプト入力(点・ボックス)を加えることで、セグメンテーションを補正できるインターフェースを持たせることで、AIモデルと人間の協調検査が可能になります。
- 監視セキュリティ:防犯カメラ映像で特定人物や不審物を自動検出・追跡し、アラート生成が可能になります。また、ヘルメットやベスト、手袋などの各現場における必要な装備検知や、器具や材料などの検出・追跡も可能となります。
最新技術の実装でより最適な解を
AI技術の進化は目覚ましく、企業によっては、技術開発部やDX推進部などで本務にプラスAI開発を兼任で行う場合もあるため、最新技術を追っていくのは時間的、手間的に難しいこともあるでしょう。
また、過去に導入したAIモデルが現状にそぐわなくなってきている、というお悩みも最近よくお伺いしています。
新規AI導入検討、既存AIモデルの改善など、いずれも対応可能ですので、まずはご相談ください。
参考文献
Segment Anything Model 2 (SAM2)
Segment Anything Model 2 (SAM2) & SA-V Dataset from Meta AI
SAM2: Segment Anything in Images and Videos
FacebookResearch(現Meta)のGitHubリポジトリ
ぜひお気軽にお問い合わせください。
Contact us
お問い合わせ
画像認識をはじめとするAIのことなら是非OkojoAIに!ご相談ベースで構いませんので、遠慮せずお気軽にお問い合わせください。


